A headline you have almost certainly seen, in one variation or another: ChatGPT drinks a bottle of water for every question you ask it. Sometimes the version is per email, sometimes per twenty questions, sometimes just per conversation, but the underlying claim is consistent. You typed a sentence into a chatbot. Somewhere a bottle of water disappeared.
The headline traces back to an actual peer-reviewed paper by Shaolei Ren and colleagues at UC Riverside and UT Arlington, originally posted in 2023 and updated through March 2025. The paper does not claim a bottle per question. It claims GPT-3 needs to consume a 500 mL bottle for every 10 to 50 medium-length responses, depending on where and when the inference runs. Somewhere between the original publication and the secondary coverage, “10 to 50 responses” became “per question,” then “per email,” then a piece of internet weather everyone has felt and almost nobody has read the source for.
 Ren et al., updated March 2025, from the paper’s introduction. The original claim is “10 to 50 responses per bottle,” not a bottle per question. The Washington Post’s popular summary as “a bottle of water per email” is the version most people now remember.
Ren et al., updated March 2025, from the paper’s introduction. The original claim is “10 to 50 responses per bottle,” not a bottle per question. The Washington Post’s popular summary as “a bottle of water per email” is the version most people now remember.
That gap, between what the original paper measured and what the internet now remembers, is where the actual number lives. The defensible figure for a current text query is around five drops. The bottle figure is from a 2020-era model, telephone-gamed since. The aggregate, calculated across hundreds of millions of weekly users and the power plants supplying the data centers, is genuinely large and growing.
Where the water physically goes
Data centers do not consume water for the artificial intelligence itself. The AI is software running on silicon. Silicon running at full inference load generates considerable heat. Hot processors must be continuously cooled or they degrade, and the cheapest, most prevalent method of cooling a building full of processors is to spray water across warm surfaces and allow evaporation. The evaporation extracts heat from the surrounding air, identically to the way perspiration extracts heat from your skin. That mechanism, repeated at industrial scale, is what an evaporative cooling tower performs. Of every liter of water introduced into the cooling tower, roughly 80 percent evaporates in typical cooling-tower designs. The remainder exits as discharge. The 80 percent is gone, atmospheric, no longer potable.
It is the water you could physically stand next to, observe, and say “this much went up as steam this afternoon.” It is also, for most operational data centers, the smaller half of the actual story.
The larger half lives upstream. The processors require electricity. The electricity originates at power plants, and most US electricity still comes from thermoelectric plants, which boil water to drive turbines and consume additional water to condense the steam back to liquid. The Lawrence Berkeley National Lab’s 2024 data center report places US data centers’ direct on-site water consumption (water that evaporated and is gone, not borrowed and returned) at approximately 66 billion liters in 2023. The same report places indirect water consumption, the water consumed at power plants generating the electricity those data centers used, at approximately 800 billion liters. Roughly twelve times larger.
When a sustainability report announces that a query consumes 0.26 mL, that figure represents the cooling tower water exclusively. It is accurate. It is simply not the totality of the water consumed. The larger volume is sitting at a coal or natural gas plant several states away, and most published figures account for it separately or fail to account for it whatsoever.
The third frame is the one that headlines confuse most consistently. Training a frontier model is essentially a one-time, intensive event. The model is trained for weeks or months, on thousands of accelerators running continuously, after which the trained weights get distributed across serving fleets that subsequently answer user queries. The water cost of training and the water cost of inference (the industry word for what happens every time the model answers a query) represent fundamentally different categories of expense. Ren’s team estimated that training the original 175-billion-parameter GPT-3 across Microsoft’s US data centers consumed approximately 5.4 million liters total, of which roughly 700,000 liters evaporated on site. After several months of production deployment, the training cost gets dwarfed by the cumulative water cost of all the queries the model subsequently answers. Inference is small per query and enormous in aggregate. Training is large once and then progressively shrinks in relative significance as the model accumulates served users. Most “AI uses X liters of water” headlines do not specify which category they are referencing.
The per-query number worth holding
In August 2025, Google published the cleanest per-prompt environmental figure any frontier laboratory has currently placed on the record. Their published estimate, accompanied by methodology, indicates the median Gemini Apps text prompt consumes 0.26 mL of water, 0.24 watt-hours of energy, and emits 0.03 grams of carbon dioxide equivalent. About five drops of water per prompt. A teaspoon holds roughly a hundred drops, for scale.
 Google Cloud, August 2025. The headline figure. The body of the post details which water it counts (on-site cooling) and which it doesn’t (power-plant water).
Google Cloud, August 2025. The headline figure. The body of the post details which water it counts (on-site cooling) and which it doesn’t (power-plant water).
Google’s 0.26 mL counts only the water that evaporates in the data center’s own cooling towers. It does not count the water used upstream at the power plant to generate the electricity that ran the prompt. Add the upstream water and you roughly double the figure on a clean grid, and run higher on a coal- or gas-heavy one. Shaolei Ren, the lead author of the original water paper, pushed back on the disclosure in press coverage when the Google number landed, arguing the disclosure left out the larger half on purpose. His phrasing was that they were “just hiding the critical information.” The on-site cooling water tells you about the data center’s engineering. The upstream water tells you about the grid. Only the first one is in the headline.
Two months earlier, in June 2025, Sam Altman wrote a blog post called “The Gentle Singularity” and dropped a number for ChatGPT. He said the average query uses about 0.000085 gallons of water, which works out to roughly 0.32 mL, plus 0.34 watt-hours of energy. He did not publish methodology. He did not specify which model. He did not say whether the figure included the upstream water. As corporate disclosures go it is closer to a Tweet than an audit. But it sits next to Google’s 0.26 mL, in roughly the same neighborhood, and that neighborhood is in single-digit milliliters per query for current top text models.
A useful mental anchor: low single-digit milliliters per query at the data center for current text models, plus roughly the same again upstream at the power plant. Google’s 0.26 mL and Altman’s 0.32 mL sit at the cleaner end of that range. When someone tells you a query consumes a bottle of water, what they’re quoting is a five-year-old paper about a substantially less efficient model. The figure may already have been off in the underlying source the paper relied on, and was further telephone-gamed by secondary coverage from “10 to 50 responses per bottle” into “one query, one bottle,” with the on-site-only caveat dropped in either direction.
Why headlines disagree by 100x
The same question can produce a 0.26 mL answer or a 50 mL answer depending on who is counting.
The first is which model you measured. GPT-3, the model Ren’s paper benchmarked, came out in 2020 with 175 billion parameters, ran on the hardware of its time, and was served at the efficiency of its time. Today’s serving stacks are roughly an order of magnitude more efficient per token. The independent engineer Sean Goedecke worked through this in a careful 2024 post arguing the number is closer to 5 mL than 500 mL per chat. His math splits the difference two ways. He argues that Ren’s “10 to 50 responses per bottle” is better read as “10 to 70 pages of model output,” which translates to several typical conversations rather than several typical responses. On top of that, five years of model and hardware progress have brought another order of magnitude in efficiency. The model-progress argument is uncontroversial. The denominator argument hasn’t been publicly addressed by Ren’s team; either, or both, would explain why current per-query figures land where they do.
The second is what you count. Google counts on-site cooling water for the median prompt. Altman counts something he calls average and does not specify the scope. Ren counts on-site water for medium-length prompts on GPT-3. Some popular numbers count training amortized over inference. Some mix consumption (water that evaporated and is gone) with withdrawal (water that was taken out of a river and partly returned). Most public figures do not foreground the difference, because foregrounding it is bad headline material.
The third is where the data center is. Ren’s Table 1 is the cleanest single illustration of this. The same GPT-3 inference, served from different Microsoft data centers, ranges from 10.5 responses per bottle in Washington state to 70.4 responses per bottle in Ireland. Same model, same prompt, same company, roughly seven times more water in the worst location than the best. Hotter and drier means more cooling. Coal- and gas-heavier grids mean more thermoelectric water at the power plant. The location is not a footnote. The location is the bulk of the spread.
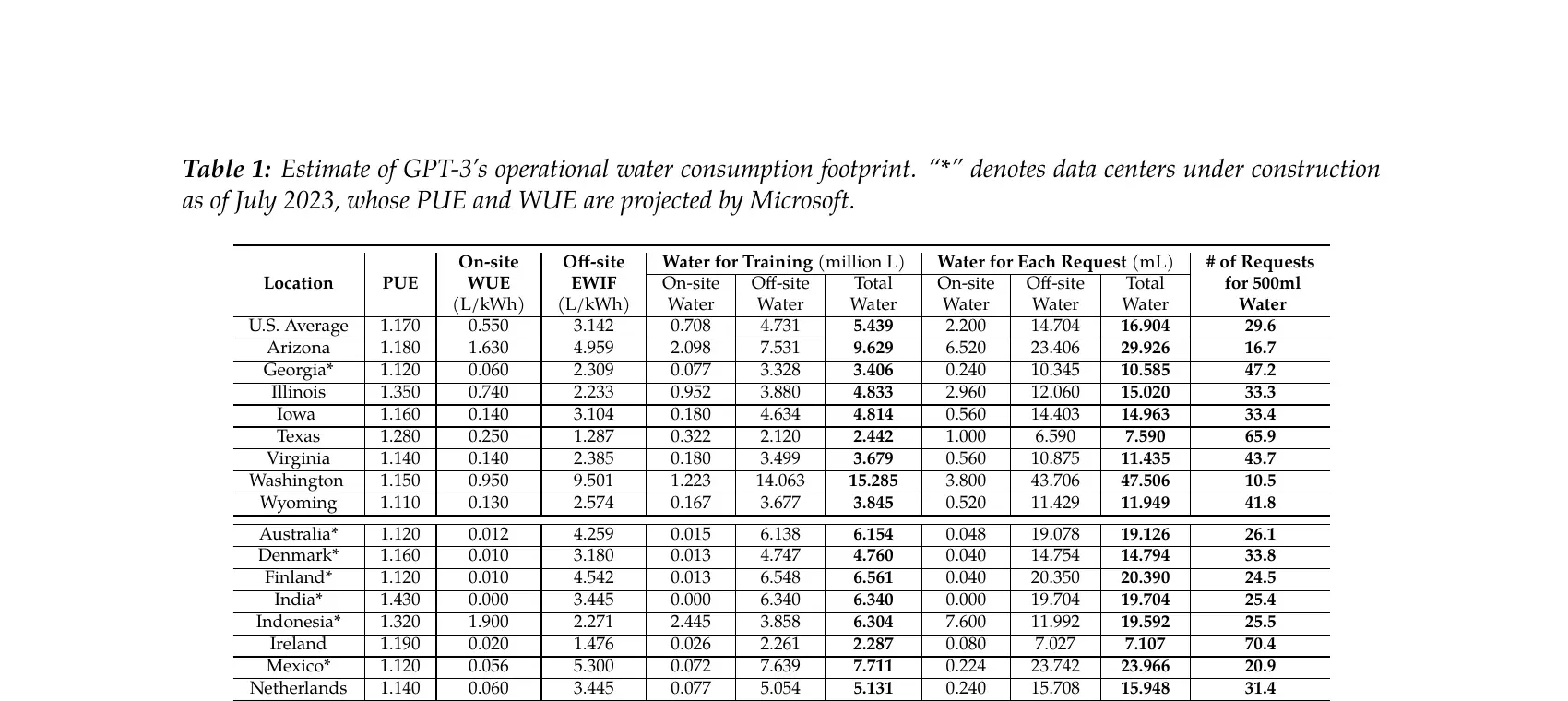 Ren et al., March 2025. Same model, same query, seven times the water depending on the data center.
Ren et al., March 2025. Same model, same query, seven times the water depending on the data center.
Three things complicate the picture. Reasoning models, the kind that “think” through a problem before answering, run several times the compute of a regular chat, and the water bill scales the same way. Image generation runs heavier per request than text by roughly an order of magnitude. And Microsoft is beginning to deploy a new data center design that uses zero water for cooling, which removes the on-site cooling water entirely but pushes more load onto the grid, moving the water cost upstream rather than eliminating it.
The aggregate, which is the part that grows
A few drops of water per text query, multiplied by ChatGPT’s hundreds of millions of weekly users (OpenAI said the platform was on track to reach 700 million in August 2025), plus Gemini, Claude, Copilot, and the remainder of the competitive field, plus the training runs nobody publishes, plus reasoning queries, plus image generations, plus the video generations currently arriving, accumulates into a number that is no longer small.
The International Energy Agency’s April 2025 “Energy and AI” report put global data center water consumption (of which AI is a fast-growing share, alongside other compute) at roughly 560 billion liters per year currently, and projected it will reach roughly 1,200 billion liters per year by 2030 in their base case. About two-thirds of that is upstream electricity generation. About one-quarter is direct cooling. The rest is semiconductor manufacturing, the water used to make the chips that the data centers run.
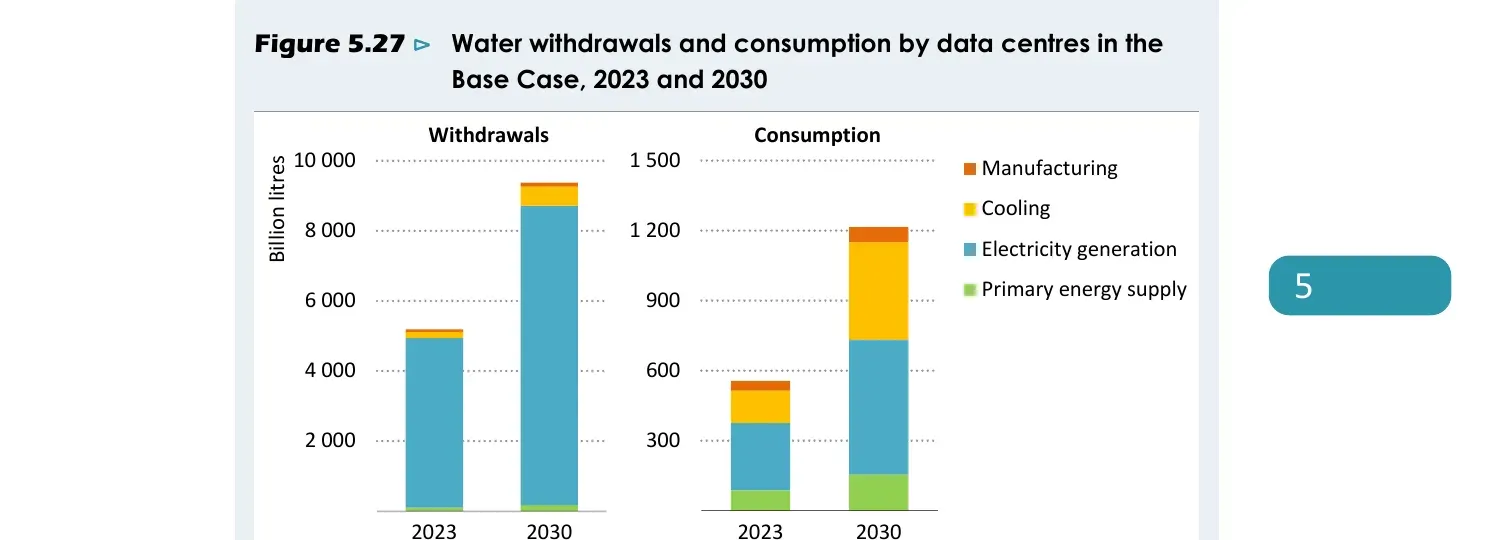 IEA Energy and AI, April 2025. Withdrawals and consumption both more than double by 2030. Electricity generation (the upstream water at the power plant) and primary energy supply together dominate every bar.
IEA Energy and AI, April 2025. Withdrawals and consumption both more than double by 2030. Electricity generation (the upstream water at the power plant) and primary energy supply together dominate every bar.
The big providers’ own disclosures point the same direction. Microsoft cut its per-unit water use roughly 39 percent across three years. Meta’s newer sites, built around dry cooling, are the most water-efficient any hyperscaler has publicly disclosed. Google’s 2024 fleet kept climbing in absolute volume even as efficiency improved. Per-unit, the curve goes the right direction. Fleet size grows faster.
What the trend lines are not doing is decreasing in absolute terms. Per query, the AI is substantially more efficient than it was three years ago. Per company, the data center fleets are considerably larger than they were three years ago and continuing to expand. The IEA’s projection assumes the per-query efficiency gains continue arriving and the build-out continues arriving, and the per-query gains lose the contest. The total roughly doubles between now and 2030.
Per query, the water cost is a few drops. Per planet, the cumulative number requires genuine infrastructure planning.
What to do with the number
The next “AI uses X liters of water” headline comes with three questions worth asking. Which model. What scope. Where the data center is. With those three answers, almost every apparent disagreement between published figures resolves.
If a piece quotes a bottle of water per query, the figure traces back to a study of GPT-3, a 2020 OpenAI model from the same lineage that eventually led to ChatGPT. Today’s models are roughly an order of magnitude more efficient. The number is stale unless the piece names that source. If a piece quotes 0.26 mL and does not mention the upstream water at the power plant, the number is accurate but partial. If a piece quotes a national or global aggregate, look for whether the figure includes upstream electricity, because two-thirds of the total is sitting there. If you want to investigate further, the Ren paper remains the canonical mechanism explainer; the Google disclosure provides the cleanest per-prompt mathematics currently published; the IEA report is the appropriate starting point for sector-level forecasts. For the same partial-truth-told-fluently pattern applied to AI’s own outputs, how AI hallucinates covers the model-side mechanism.
The water you consumed asking a chatbot for a recipe earlier today is, on a clean grid, around a milliliter. The water the global data center fleet will consume by 2030 is roughly double what it is now. Per query, your habit is not the dial worth worrying about; the aggregate is. Ask for the recipe. Push for the policy on grid mix and data-center siting.